Store data the smart way
This post is part of the series “The Zen of Data Pipelines” which explores how to build scalable and robust data systems. Most of the ideas and best practices described in this series were learned while implementing and maintaining a large scale data pipeline at F-Secure for the Rapid Detection Service. You can find more posts of this series in this blog or all series content on Gitbook.
The last step of any data pipeline is to store the data. Regardless the data format and requirements for the processed data, in most cases the storage requirements include high performance reads and writes to low prices, high scalability and high availability. The ideal data storage covers all requirements and while keeping low maintenance on the infrastructure side. Data storage is an essential subsystem of the whole pipeline. The more robust and automated backups, replication and high availability are, the better.
Most databases are heavy on resources, expensive to maintain and sometimes cumbersome to ensure that data is replicated and available all the time. In addition, backups and data downsizing often affect the storage performance to serve user requests. Naturally, more resources can remediate these issues to a certain extent, but we aim at building a performant and low cost data pipeline.
The best solution is to store all data in a cloud-based file system (CFS) and build the tooling for creating temporary services and databases that ingest data from the CFS when necessary.
Storing data in CFS allows us to leverage services like AWS S3 [1], Cloud Storage [2] or MS Azure blob storage [3] to get high available, replicated, affordable data storage, automatic backups, hot/warm/cold storage and other handy features out of the box. These features come with almost no maintenance required. The underlying idea is that it is easier, safer and cheaper to store large amounts of data in those services than maintaining a complex data storage like Elasticsearch or any large scale SQL/NoSQL clustered database. If and when a subset of data needs to be ingested by other databases than CFS, then it is easy to spin them up and load the necessary data. Using disposable datastores for ingesting and serving temporary data sets helps to save costs and provides flexibility. An example of this storage architecture is presented in the Figure 1.
CFS architecture
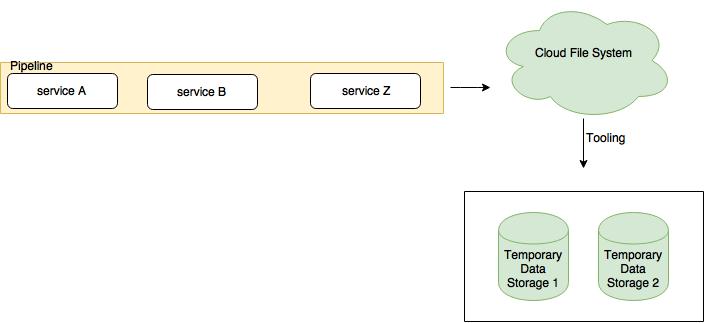 Fig. 1 Architecture in which data is stored in a Cloud File System after it has been processed. If needed, spin up data storages or services that ingest a subset of data for temporary usage
Fig. 1 Architecture in which data is stored in a Cloud File System after it has been processed. If needed, spin up data storages or services that ingest a subset of data for temporary usage
Unfortunately, in many cases the system requirements do not fit this architecture. The data processed by the pipeline may need to be accessible in near real-time in a determined format (e.g. in a relational database). This requires the data to be stored in a relational database right after it is processed. In any case, it is good practice to try to offload as much data as possible to a CFS. As a rule of thumb, aim at designing the system architecture so that you have that flexibility. In many cases, the best fit is an hybrid data storage approach (see Figure 2). This approach has the best of both worlds: the data is always stored in CFS and partial, fresh data is stored in other databases. The idea behind the hybrid data storage approach is that not all the historical data needs to be accessible in near real-time. Thus, instead of keeping all the data processed by the pipeline in a replicated and high available database cluster - which is hard and expensive to maintain - the idea is to keep only the most recent data in the hot storage and offload the rest to a cold storage (the CFS). Whenever clients need the old data, having the tooling to move data from the cold storage to hot storage is essential. Again, this can be done by spinning up temporary and disposable hot data storages to take the old data in without affecting the main databases.
CFS architecture and external services
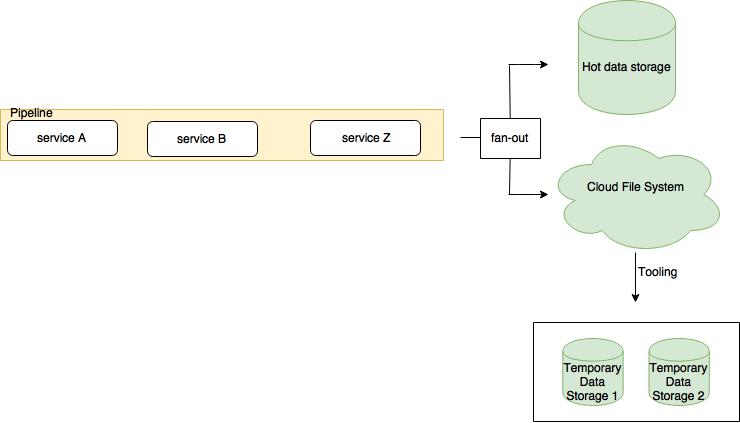 Fig. 2 The system may require that the data is available in a particular data storage after it has been processed. The data can be fan-out to both CFS and specific data storage in these cases.
Fig. 2 The system may require that the data is available in a particular data storage after it has been processed. The data can be fan-out to both CFS and specific data storage in these cases.
An important thing to have in mind with this architecture is the addressability of the data stored in the cold storage and the tooling to recover it. Before storing the data in the cold storage, think about what are the addressability requirements. Having a fine-grained addressability of the cold storage gives system possibility to recover data from the cold storage with more precision and save on both bandwidth and time when transferring data from cold to hot storage.
Takeaway: After the data is processed, store the data in a cloud file system (CFS). The CFS will provide cheap storage with high availability, backups, replication, large bandwidth and low maintenance out of the box. When needed, transfer the data from the CFS to other data store on the fly using proper tooling. If the system requires the data to be available right after the processing in a specific data storage or service, adopt a cold/hot architecture: fan-out the data to both CFS and specific data storage while maintaining a shorter retention policy for the hot data.