Why have one pipeline when you can have multiple
This post is part of the series “The Zen of Data Pipelines” which explores how to build scalable and robust data systems. Most of the ideas and best practices described in this series were learned while implementing and maintaining a large scale data pipeline at F-Secure for the Rapid Detection Service. You can find more posts of this series in this blog or all series content on Gitbook.
The pipeline image is a great way to abstract a system where input data is received, processed and stored. Visualizing a data pipeline makes it easier to think and communicate about the system. However, when it comes to large scale implementations what we aim at is to create multiple data pipelines which work in parallel with dedicated resources. A parallel pipeline is called pool and is an independent processing unit.
The basic principle is that each pool is responsible for a subset of the input data and has its own resources, completely independent from other pools. If, for example, the processing services are containers running on top of a DC/OS or EC2 cluster, each pool must have a dedicated cluster. Each pool must also have its own messaging resources as well, which can be its own dedicated cluster or virtual host.
Not only a pool has its own dedicated resources but it also processes its own shard of data. The data input must be split into as many shards as the number of pools and each of the pools consumes one shard of input data..
Splitting the data pipeline into multiple pools has several advantages. First, it offers a protection against single point of failure. Imagine that our pipeline needs to process data from several data sources. Imagine also that one of the data sources unexpectedly starts sending so much data that the pipeline is not able to handle everything without a significant delay. Since all the data sources are being processed by the same pipeline - and same resources - all data processing will be affected. Or what if a data source sends corrupted data and some services cannot handle it gracefully and break? Since the services are shared by all data sources, the whole pipeline halts. Basically, having only one data pipeline is the same as putting all eggs into one basket: if something goes wrong, the whole data pipeline is affected.
In addition to preventing single point of failure, splitting the pipeline into pools helps to think about resources when deploying and managing the system. A good practice is to roughly know what is the throughput and the amount of data a pool can handle without hiccups. This is a good measure to have in mind when the data sources increase in number or load. If you are expecting a new data source to increase considerably the volume of data fed into the pipeline, then you may as well deploy a dedicated pool (or multiple pools) for that data source. You will start seeing pools as your processing units which can be deployed in parallel to scaling the pipeline horizontally.
As an example, let’s assume the data processing is done by service A, B to Z (see Fig. 1). First, the data input is sharded in as many shards as number of pools. The relation of data shards to pools is 1:1. Assume that the service A reads data from the source buffer, processes it and publishes it to the next buffer, where service B will consume the data, transform it and publish it to the next buffer. The same process goes on until service Z stores the final data in the data store. If for some reason the Pool B halts, the remaining pools will keep processing data. As you can see in Fig. 1, it is easy to scale the pipeline horizontally. Just cut a new shard from the data input and add a new pool to the pipeline.
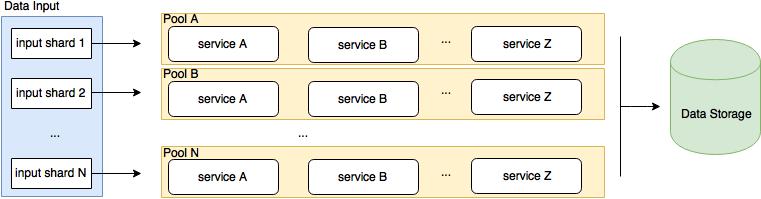 Fig. 1 Design of a data pipeline using multiple pools. Each pool has its own services and resources. The input data is sharded and pushed into each pool for processing. The processed data from each pool will be stored in the same data storage.
Fig. 1 Design of a data pipeline using multiple pools. Each pool has its own services and resources. The input data is sharded and pushed into each pool for processing. The processed data from each pool will be stored in the same data storage.
Takeaway: Split your pipeline into pools with dedicated resources. Pools will prevent single point of failures, make the whole system more robust to failures or sudden increase of data load and will help you to scale the system.